Unlocking Cross-Selling Potential: How Machine Learning Enhances Insurance Rider Recommendations
In this article, I explored how machine learning can optimize insurance rider suggestions, with a special shoutout to ChatGPT for making the journey smoother and more enjoyable. Thanks to its assistance, I was able to quickly navigate challenges, refine ideas, and stay entertained throughout the process.
Overview
Data can be a helpful guide, whether the economy is thriving or facing challenges like high inflation. During good times, it can fuel business growth, and in tougher times, it can uncover opportunities like cross-selling. For example, offering insurance riders as add-ons to existing customers could help maintain profitability when people are more cautious with their spending. Given that we’re currently in an era of high inflation (as I’m writing this), I’ll share a business case to explore how this approach might work, demonstrating how data can offer valuable insights when used thoughtfully.
So, to all the companies out there considering outsourcing your data to a third party—without having total control over it—maybe pause for a moment. Think twice, thrice, or even to infinity before making that call. After all, your data is often more valuable—and lasts longer—than your business itself. And once it’s in someone else’s hands, well, youdefinitelyprobably lose all control. Comfortable with that? Didn’t think so.
Background
Before we begin, let me share a bit of background to set the stage. I’ve been working as a solution architect for over 10 years, focusing almost entirely on system integration—primarily connecting users to databases. You could say my work has revolved around OLTP.
That said, I’ve always been curious about data lakes, machine learning, and OLAP architectures, as they offer a very different approach. For example, OLTP databases rely on normalization, while OLAP requires denormalization to speed up aggregations for analysis. This contrast intrigued me, along with tools like Hadoop, Parquet, and Spark. I’ve heard about these technologies for years but hadn’t had the chance to dive into them—at least not until last year. Over the recent Christmas holiday, I finally set aside time to explore data architecture and its tools. I’m still learning, so if you find areas where my article could be improved, I’d love your feedback. Please feel free to share your thoughts in the comment section—I truly welcome them!
I’ve been working in the insurance industry for many years—way before I became a solution architect (I actually started as a software engineer in the insurance world, but that’s not too important). So, naturally, my business is closely tied to the insurance industry. Not surprising, right?
Just a bit of basic business knowledge: an insurance policy can generally be divided into a few major parts. First, there’s the customer part, which is further split into policyholders, insured individuals, and beneficiaries. This section includes important information such as age (a very crucial variable), annual income, occupation, and other demographic details. Then, there’s the product part, which covers the main products (typically the life insurance itself, with a face value or sum insured) and its add-ons—what we usually call riders. For example, if you want to combine your life insurance with health insurance, you can buy the main life insurance product and then add a health rider to it. Of course, this comes with an increase in your premium.
Enough about insurance knowledge—don’t worry, this is still a tech article, not a crash course in insurance business!
Business Case
Back to business case. Let’s say I have a massive amount of submission data from customers looking to buy an insurance policy. And this submission data is packed with all sorts of information—policyholders, insured individuals, beneficiaries, and, of course, the product the customer wants. The data is in JSON format (because, let’s face it, JSON is still my favorite over XML). There’s plenty more data, but for this particular use case, we’ll just ignore the irrelevant bits.
Data Preparation
So, how do I approach this? In short, I need to create a clean data flow. First, I start with the submission data. Then, a trigger starts an ETL job, which divides the data into different management sections. The tools I use? Well, we’ve got S3 for data storage (or should I say, the data lake), Apache Spark (with AWS Glue and PySpark) for all the ETL magic, and Anaconda for training the model. Apache Airflow? Hold on—it’s not in this article, but I’m definitely curious to dive deeper into it soon.
I came across some really useful references, and one of them was this article from Alicloud about data warehouse solutions. If you’re interested, check it out here: Alicloud Data Warehouse Solutions. Trust me, it’s a great read! From that article, I learned a lot about big data warehouse solutions, especially the distinction between concepts like Application Data Store (ADS), Data Staging Warehouse (DSW), Data Warehouse for Distribution (DWD), and Operational Data Store (ODS).
And because I’m all about efficiency, here’s a summary of those terms (thanks, ChatGPT!) in the table below.
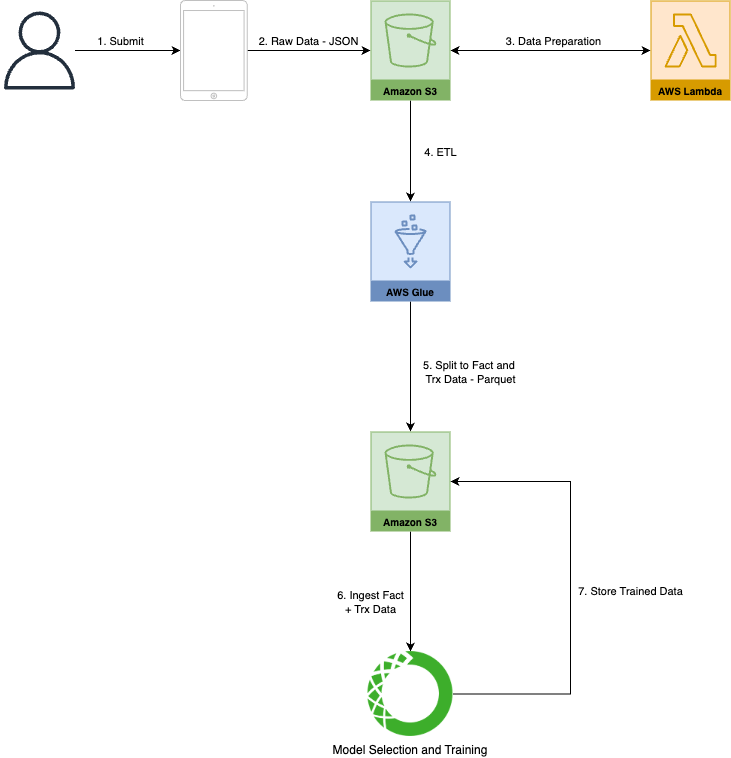
Data Flow Architecture
To better illustrate how all these components come together, let me walk you through the architecture. The flow begins with the submission data, which triggers an ETL job. The data is then processed, cleaned, and organized into various management sections. This is where Apache Spark and AWS Glue come into play for ETL magic, transforming the refined data into something usable. From there, it’s stored in an S3 data lake, ready for further analysis.
Once the data is in the lake, the next step is organizing it for machine learning. We use Anaconda for training the model, which takes the clean, processed data to find valuable insights. Along the way, data is split into various layers based on its purpose—whether that’s staging, operational, or analytical—and stored accordingly.
Now, to help visualize this process, here’s an architecture diagram that shows how everything connects, from data ingestion to model training.
Exploratory Data Analysis
The goal here is to create a set of features that will help the machine learning model understand the patterns and relationships within the data. I’m using supervised machine learning for this task, meaning that we already have labeled data (i.e., historical submissions) that show which add-ons customers have chosen in the past. With this labeled data, the model learns from past examples to make accurate predictions about future add-ons.
I’ll need to carefully select which features to include, making sure they are relevant and don’t introduce too much noise. For example, while “age” might be a strong predictor of certain add-ons, “income” could influence the likelihood of purchasing higher-tier riders. Once these input variables are defined, they are passed to the machine learning algorithm for training.
This is where feature engineering comes into play. We may need to transform or combine certain variables to make them more useful for the model. For example, categorizing age groups (like 18-25, 26-40, etc.) or combining income brackets with occupation data could reveal insights that individual variables might miss. Once we have our well-defined set of input variables, we’re ready to train the model and start making predictions.
Please note I used random data set, with some data are skewed on purpose to get better results. No real data are involved.
Variable Correlation
Before diving into the model training, it’s important to evaluate the relationships between the input variables and the target variable. Using Pearson correlation, we can measure the strength and direction of these relationships to identify which features are most relevant to predicting the “targeted rider” and which ones might add noise to the model. This analysis helps prioritize impactful features and streamline the data for better machine learning performance.
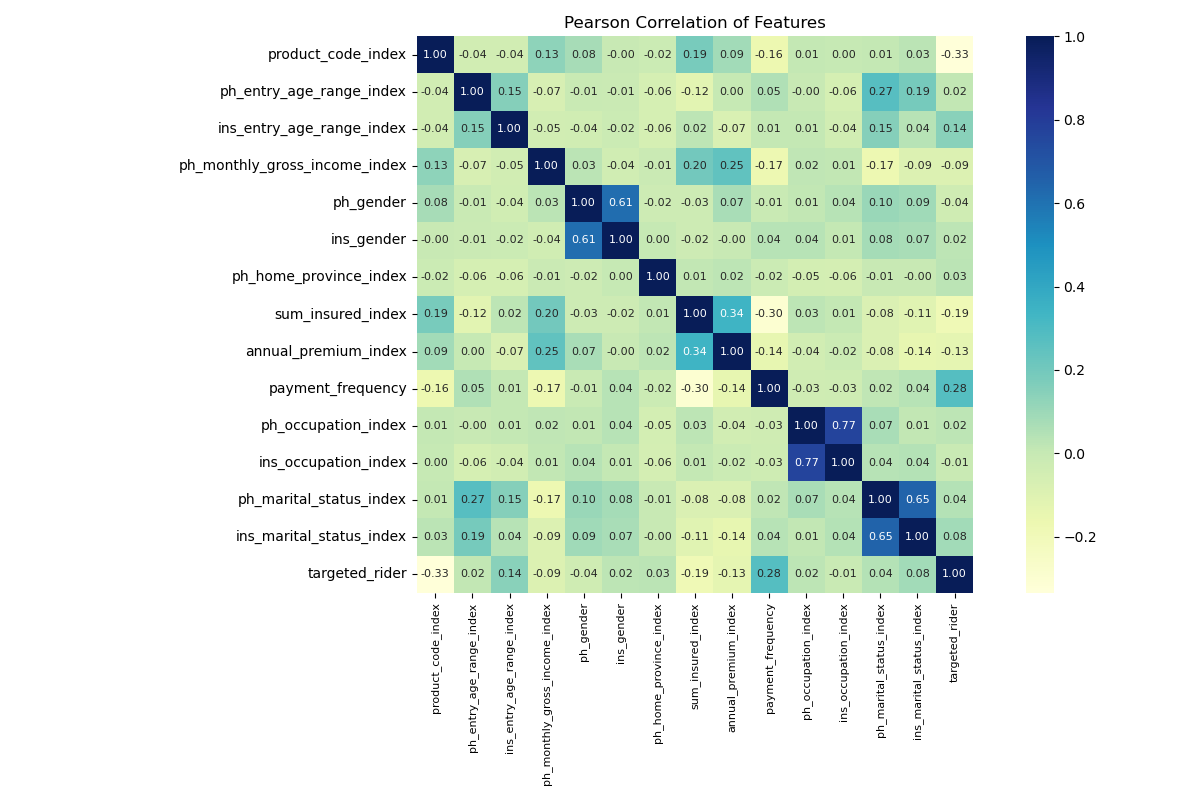
To further refine the input variables for the machine learning model, I conducted a Pearson correlation analysis to understand the relationships between features and the target variable, which is the “targeted rider” in this case. The heatmap above visualizes these correlations, with values ranging from -1 (strong negative correlation) to +1 (strong positive correlation). Features like “payment frequency” and “annual premium” show moderate correlations with the targeted rider, suggesting they might play a significant role in the model’s predictions. Meanwhile, some variables, like “policyholder gender,” exhibit very weak or no correlation, indicating they may not contribute much to the model. This analysis helps narrow down the most relevant features, reducing noise and ensuring the model focuses on what truly matters.
Data Set Training and Evaluation
To evaluate the performance of the models, I used three supervised machine learning algorithms: Logistic Regression, Random Forest, and Gradient Boosting (though only two visual outputs are shown here). The results are measured using the AUC-ROC (Area Under the Receiver Operating Characteristic Curve), which indicates how well the model separates the positive and negative classes.
The results from the three models reveal notable differences in their ability to handle the dataset.
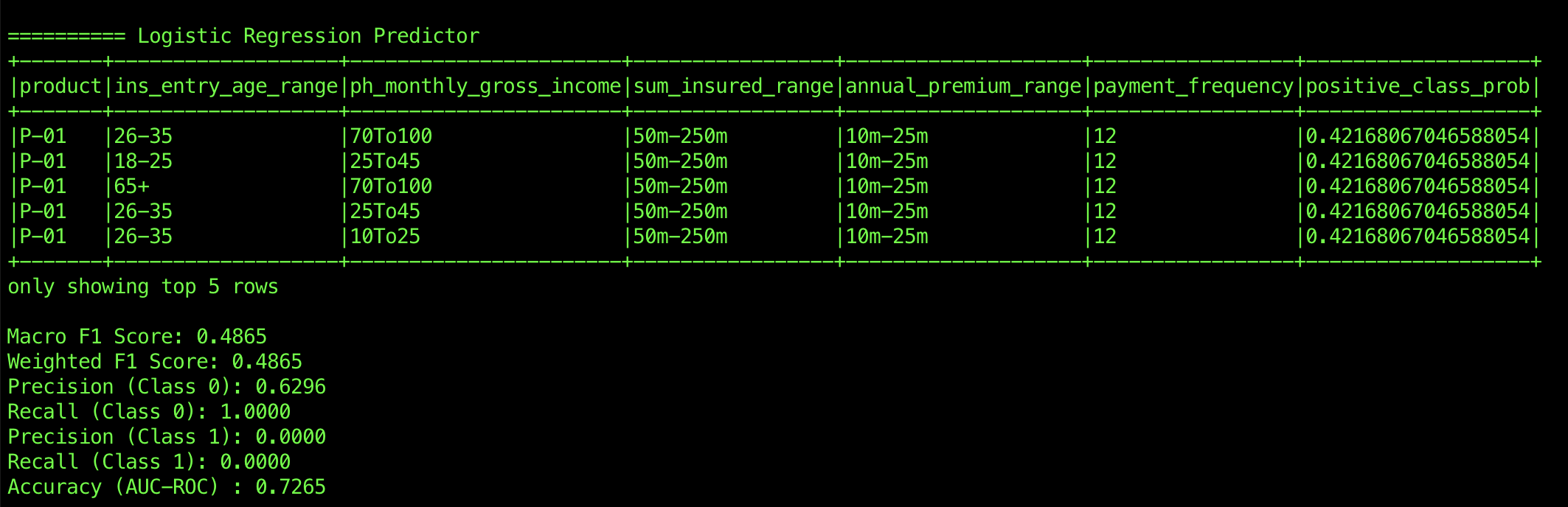
Logistic Regression, with an AUC-ROC of 0.7265, struggles with distinguishing between Class 0 and Class 1. While it achieves perfect recall for Class 0 (meaning it correctly identifies all Class 0 instances), it fails entirely for Class 1, with both precision and recall at zero. This suggests that Logistic Regression may be overly biased towards Class 0, failing to learn or predict Class 1 adequately. The F1 score for Logistic Regression is relatively low, reflecting this imbalance between the two classes.
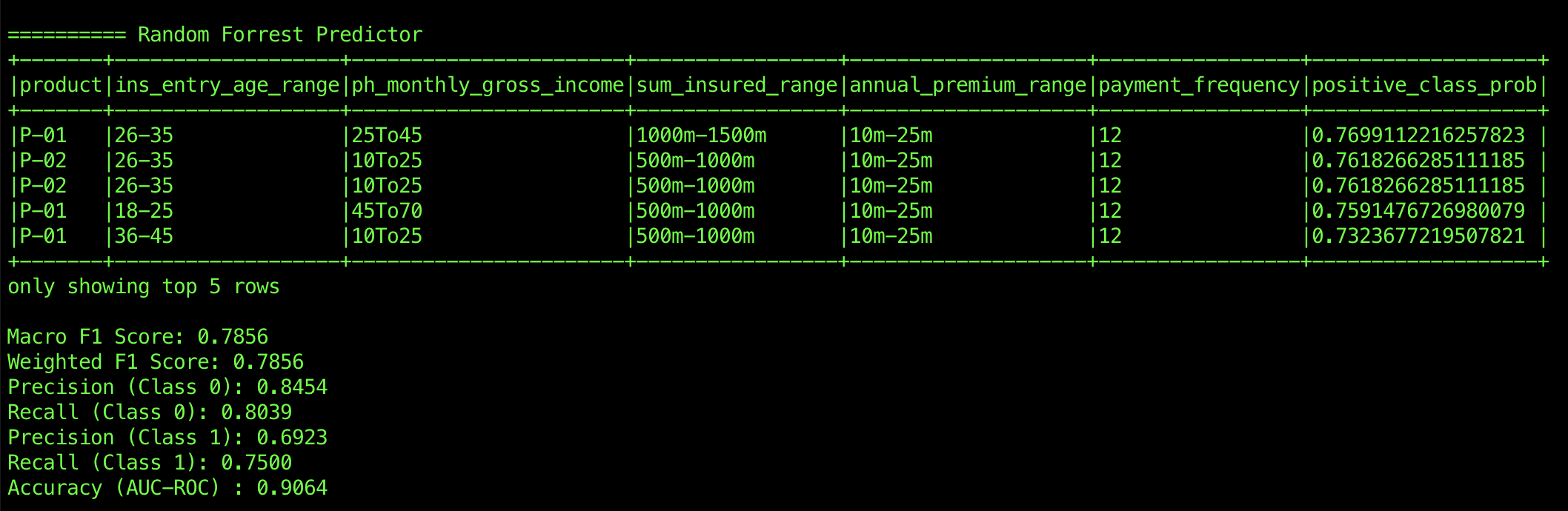
Random Forest, in contrast, shows a much stronger performance. With an AUC-ROC of 0.9064, it demonstrates excellent separation between the classes. It achieves high precision (0.8454) and recall (0.8039) for Class 0, indicating it accurately identifies both the presence and absence of Class 0. For Class 1, it performs well too, with a precision of 0.6923 and recall of 0.7500, showcasing its ability to balance both classes effectively. The Macro F1 score and Weighted F1 score of 0.7856 further emphasize Random Forest’s ability to maintain a solid performance across the dataset, making it the top performer.
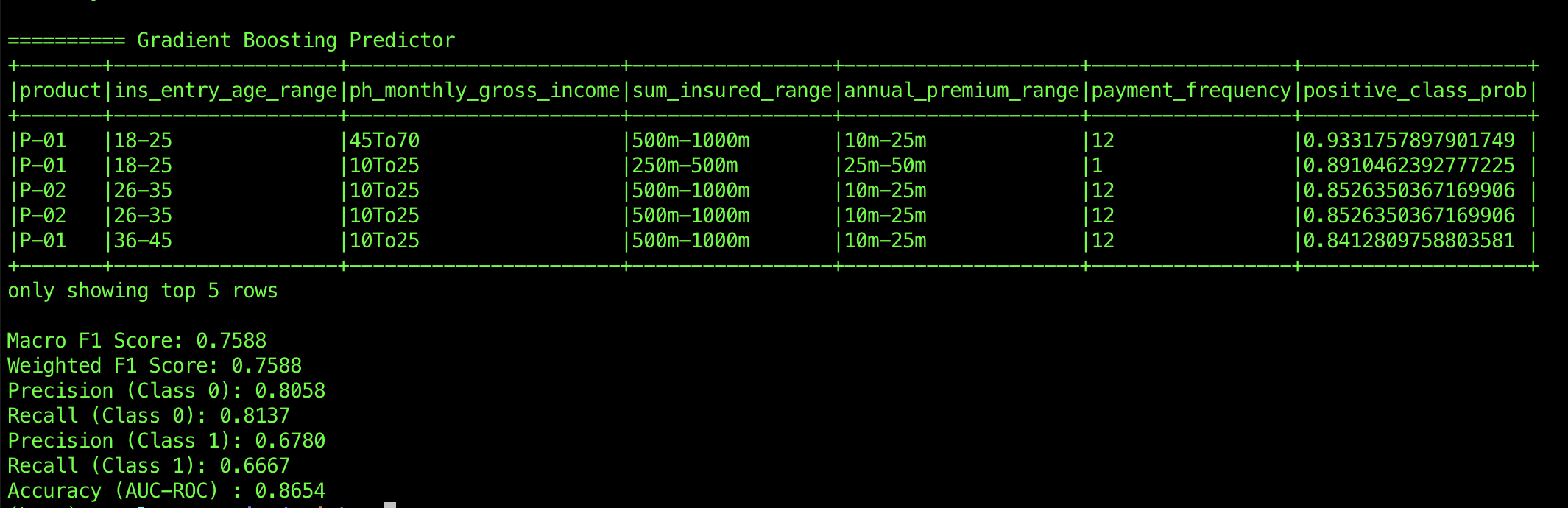
Gradient Boosting follows closely behind with an AUC-ROC of 0.8654, offering a decent separation between the classes. It achieves a good balance for Class 0, with precision of 0.8058 and recall of 0.8137. However, for Class 1, it lags slightly behind Random Forest, with a precision of 0.6780 and recall of 0.6667. Despite this, its F1 scores (both Macro and Weighted) of 0.7588 are still strong, indicating solid performance across both classes.
After evaluating the performance of Logistic Regression, Random Forest, and Gradient Boosting, Random Forest stands out as the most effective algorithm for this task. It delivers the highest AUC-ROC, indicating superior separation between the classes, and offers balanced precision and recall for both Class 0 and Class 1. Its solid F1 scores further reinforce its robustness in handling imbalanced classes. While Gradient Boosting also performed well, especially for Class 0, its slightly lower precision and recall for Class 1 make it less reliable than Random Forest in this context. Logistic Regression, although it performs well for Class 0, fails to adequately predict Class 1, making it less suitable for this particular problem. Therefore, Random Forest emerges as the clear choice for achieving the best overall performance in terms of accuracy and class balance.
Conclusion
Now, let’s take a step back and see how these insights can drive business decisions. By leveraging the predictions generated by the Random Forest model, businesses can effectively optimize their cross-selling strategies. For instance, let’s imagine a scenario where an insurance company is targeting customers for a health insurance rider. Based on the data, the model predicts that individuals in the 26-35 age range with a monthly income of 25k-45k and a sum insured between 1000m-1500m are more likely to purchase the rider. The company can now focus its marketing efforts specifically on this segment, crafting tailored offers that highlight the health rider’s benefits in a way that resonates with their needs and financial situation.
In a real-world case, the model could suggest offering P-01, the health rider, to these customers with a personalized approach, such as a special premium discount or enhanced coverage options. This targeting can lead to higher conversion rates, as customers are presented with offers that feel relevant and aligned with their financial profile. Additionally, businesses could use similar insights to identify low- or medium-income customers in the same age group who are more likely to opt for product P-02, a more affordable health rider.
Such data-driven strategies are not just about increasing conversions—they also enhance customer satisfaction by offering the right products at the right time. When customers feel like the products being recommended to them are genuinely useful and tailored to their needs, it can significantly improve their experience and loyalty.
As we continue to refine and optimize the model, the predictive accuracy will only improve, enabling even more precise targeting and ultimately driving higher profitability for the business.
Closing
As I reflect on the challenges encountered throughout this journey, one of the most prominent obstacles was grouping the age, premium, and sum assured variables into range-based columns. These variables play a significant role in predicting insurance riders, but transforming them into meaningful features that accurately represent the customer’s profile without overcomplicating the model proved to be tricky. Age and premium, for instance, require thoughtful categorization, as their impact on purchasing behavior can vary widely across different ranges. Similarly, sum assured needs to be segmented into appropriate ranges, as these financial variables directly influence a customer’s decision to purchase add-ons, yet too many ranges could introduce noise into the model.
Selecting the most suitable machine learning algorithm also presented its own set of challenges. While Random Forest emerged as the top performer in terms of AUC-ROC and class balance, there was still a need to explore other algorithms, like Gradient Boosting and Logistic Regression, to better understand their strengths and weaknesses. The decision-making process required balancing model accuracy, ease of interpretation, and efficiency. Additionally, the learning curve for AI and machine learning can sometimes feel steep, especially when experimenting with new architectures and tools. Yet, despite these challenges, AI (ChatGPT) has proven to be an invaluable ally in this process, providing insights, generating ideas, and acting as a reliable assistant. However, just like a human colleague, AI can sometimes feel a bit “lazy” — requiring extra fine-tuning and iteration to truly unleash its full potential. Nonetheless, it remains a powerful tool for learning, discussion, and continuous improvement in the world of lifelong learning.
Now, it’s time to unlock another opportunity to leverage machine learning by exploring how it can help identify new customer segment, further enhance cross-selling efforts and drive a variety of business use cases.
References
- https://www.alibabacloud.com/help/en/dataworks/product-overview/data-warehouse-solutions?spm=a2c63.p38356.help-menu-72772.d_0_1_3_1.17091657Q1ywCy
- https://www.tandfonline.com/doi/full/10.1080/08874417.2024.2395913?af=R#d1e161