A Study Case: Building A Simple Credit Card Fraud Detection System – Part 2: Mapping Gerkhin to Kafka Streams
Part 2 will talk about mapping the Gerkhin feature file into Cucumber Step Definition and its implementation using Kafka Streams.
Overview
I described a lot about requirements and how to translate them into a Gerkhin feature file in part 1. As my promise, I will bring the story implementation. So, without further due, let’s start.
Solution
 By revisiting the user story, the main point is we need a system that collecting a set of data one-by-one and processing them in an almost real-time fashion to get the outcome. This form is a style of data stream requirements. Therefore, for this user story, we will use Kafka Streams as our solution. For the testing itself, we will use
By revisiting the user story, the main point is we need a system that collecting a set of data one-by-one and processing them in an almost real-time fashion to get the outcome. This form is a style of data stream requirements. Therefore, for this user story, we will use Kafka Streams as our solution. For the testing itself, we will use Cucumber combine with JUnit5 as our testing framework.
Cucumber
To translate the Gerkhin feature file into test cases, we need some additional libraries. First and foremost, of course, Cucumber. I will use cucumber-java8 artifact because I will use lambda style for the test cases. Considering we will run the Cucumber as part of the unit test, therefore we need to add cucumber-junit artifact and include the junit-vintage-engine to enable JUnit5 to run Cucumber smoothly.
| <dependency> | |
| <groupId>io.cucumber</groupId> | |
| <artifactId>cucumber-java8</artifactId> | |
| <version>6.8.1</version> | |
| <scope>test</scope> | |
| </dependency> | |
| <dependency> | |
| <groupId>io.cucumber</groupId> | |
| <artifactId>cucumber-junit</artifactId> | |
| <version>6.8.1</version> | |
| <scope>test</scope> | |
| </dependency> | |
| <dependency> | |
| <groupId>org.junit.vintage</groupId> | |
| <artifactId>junit-vintage-engine</artifactId> | |
| <version>5.6.2</version> | |
| <scope>test</scope> | |
| </dependency> |
Steps Definition
After we include all required additional libraries, now we need to create a step definition as our testing file. Multiple questions need to be answered before we implement a step definition.
First, we need to determine the topic’s key. As per our test scenario, we need to detect a potential fraud per credit card number. Therefore, the credit card number will be our topic’s key. This key applies to the input and output topic. After we settled with the key, we need to determine the topic’s value. As usual, we will use a DTO pattern for the topic’s value. The input DTO contains the transaction data. And the output DTO consists of the fraud flag and list of transactions because we need to summarize the total suspicious amount. Next, we need to determine the input topic name and topic output name. Finally, we need to create an empty topology file for the sake of compilation.
After all the ingredients complete, let’s build a step definition file.
| // ... code fragment ... | |
| public FraudDetectionStepDef() { | |
| Before(scenario -> init()); | |
| Given("^Customer has a credit card with account number \"([^\"]*)\"$", (String cc) -> { | |
| logger.info("Credit card no {}", cc); | |
| this.topicKey = cc; | |
| }); | |
| When("Customer transacts ${double} at {string}", (Double amount, String iso8601str) -> { | |
| Instant date = Instant.parse(iso8601str); | |
| logger.info("Transaction with amount {} and event-date {}", amount, date); | |
| final CreditCardTransactionDto transaction = getTransaction(amount, date); | |
| transactionTopic.pipeInput(topicKey, transaction, date); | |
| }); | |
| Then("Fraud flag is {string}", (String flag) -> { | |
| logger.info("Fraud flag is {}", flag); | |
| KeyValue<String, CreditCardFraudDetectionDto> kv = null; | |
| while(!fraudTopic.isEmpty()) { | |
| kv = fraudTopic.readKeyValue(); | |
| } | |
| if(kv != null) { | |
| assertThat(kv.key).isEqualTo(topicKey); | |
| fraudDetectionDto = kv.value; | |
| assertThat(fraudDetectionDto.getFraudFlag()).isEqualTo(flag); | |
| } else { | |
| assertThat(flag).isNullOrEmpty(); | |
| } | |
| }); | |
| And("total suspicious amount is ${double}", (Double suspicious) -> { | |
| logger.info("suspicious amount is {}", suspicious); | |
| if(fraudDetectionDto != null) { | |
| final Set<CreditCardTransactionDto> list = fraudDetectionDto.getSuspiciousTransactions(); | |
| final BigDecimal total = list.stream() | |
| .map(value -> BigDecimal.valueOf(value.getTrxAmount())) | |
| .reduce(BigDecimal.ZERO, BigDecimal::add); | |
| assertThat(total.doubleValue()).isEqualTo(suspicious); | |
| } else { | |
| assertThat(suspicious).isEqualTo(0.0); | |
| } | |
| }); | |
| After(scenario -> tear()); | |
| } |
Of course, when you run the test case, it will produce an error because we have implemented nothing. It is expected behavior in TDD styles. They call it the RED state. Now we need to make it GREEN.
Kafka Streams
Based on our stream topology solutions, we will use Kafka Streams for the implementation. First of all, we need to come up with a stream topology. We have one input topic as our credit card transaction record. Then we have three ways of fraud detection patterns. Because every method needs a different approach, therefore we need to split the input streams into three streams. Next, after each stream detects the suspicious transaction, they need to join back into a single output stream.
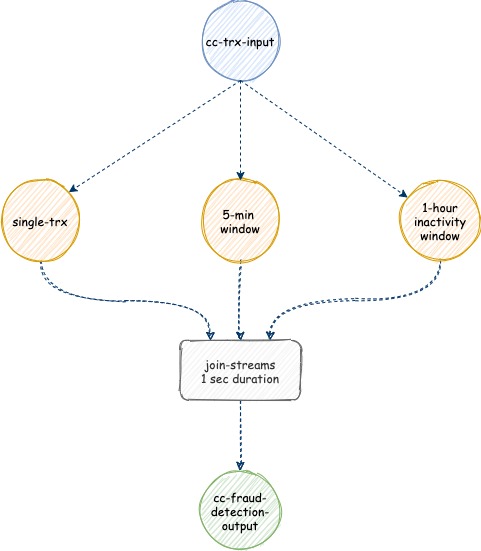 Note: we will leverage the windowing and joining functionalities inside Kafka Streams to fulfill the acceptance criteria.
Note: we will leverage the windowing and joining functionalities inside Kafka Streams to fulfill the acceptance criteria.
Single Transaction
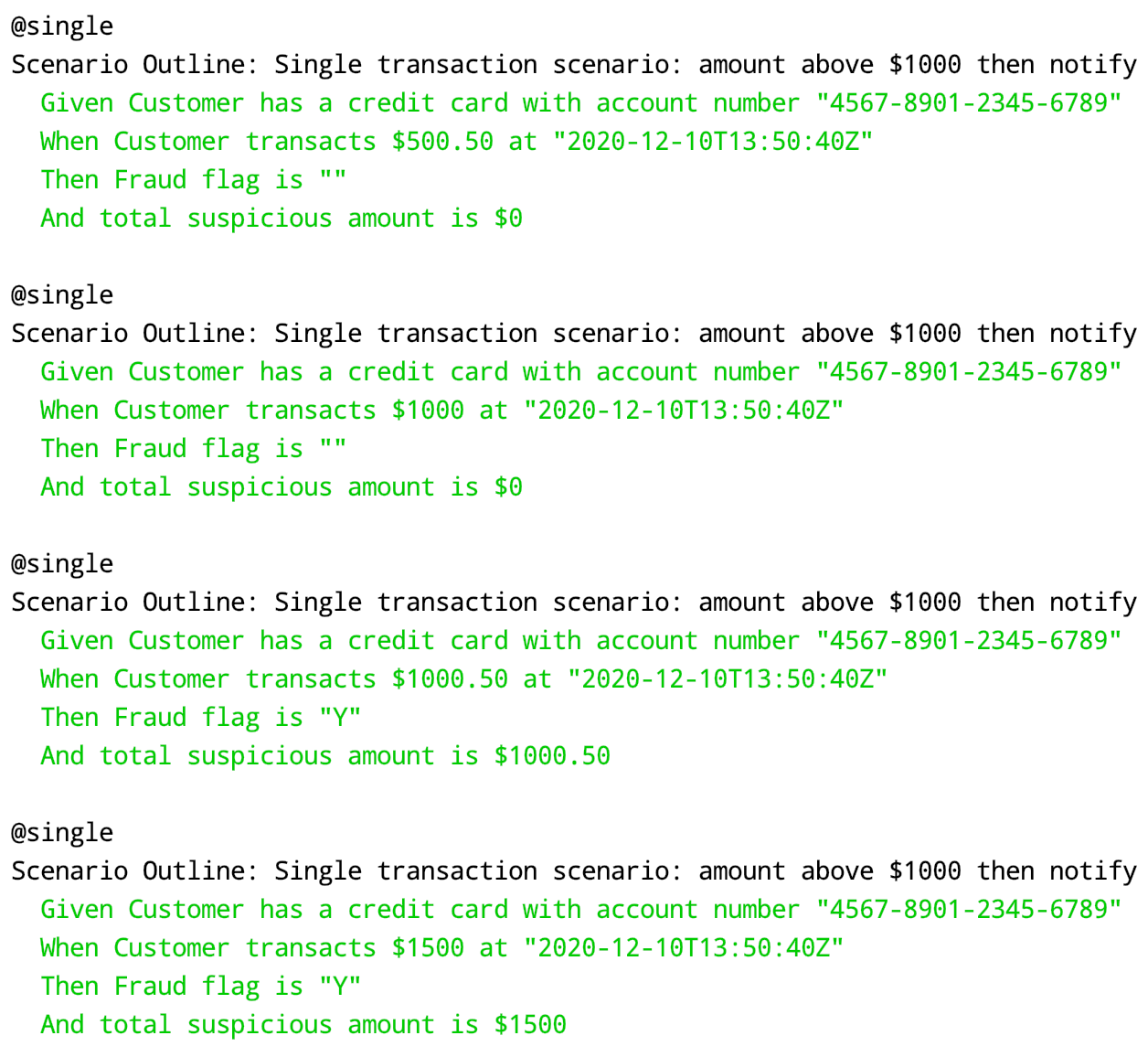
A single transaction stream is the most straightforward stream compares to the others. We only need to filter if the transaction above $1,000, then pass the record and flag the fraud indicator.
| // full code at FraudDetectionTopology.java | |
| final KStream<String, CreditCardTransactionDto> input = | |
| builder.stream(CREDIT_CARD_TRANSACTION_INPUT, Consumed.with(keySerde, creditCardTransactionSerde)); | |
| // single | |
| final KStream<String, CreditCardFraudDetectionDto> single = | |
| input.filter((key, value) -> singleThreshold.compareTo(value.getTrxAmount()) < 0) | |
| .mapValues(value -> CreditCardFraudDetectionDto.builder() | |
| .fraudFlag("Y") | |
| .suspiciousTransactions(Set.of(value)) | |
| .build()); |
5-minute Window (Hopping)
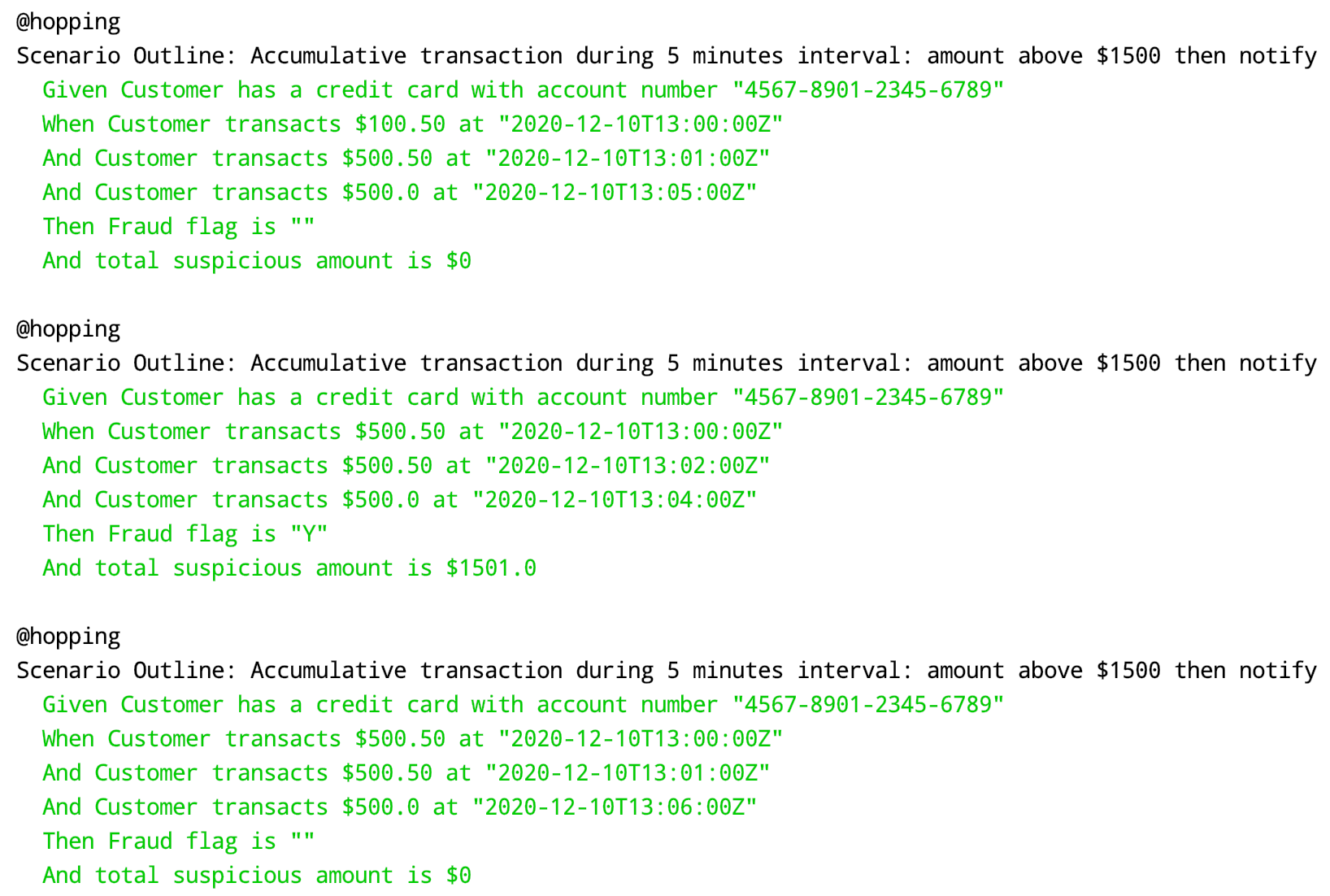
To meet these criteria, we need to implement several steps. First, we need to group by the streams per time-window. Then we need to aggregate the streams and filter a collection of transactions during 5-minutes window that has total amount above $1,500.
When it comes to windowed-streams, we need to think carefully about which windows that are suitable to meet our requirement. Based on the acceptance criteria, we need to detect transactions that could happen during 5 minutes duration at any given time. For instance, we have to detect transactions that happen between 0'-5', 1'-6', 2'-7', etc. It means the window will be overlapping with one another. Therefore we will use a hopping window approach.
| // full code at FraudDetectionTopology.java | |
| // hopping-windows | |
| final KStream<String, CreditCardFraudDetectionDto> hopping = | |
| input.groupByKey(Grouped.with(keySerde, creditCardTransactionSerde)) | |
| .windowedBy(TimeWindows.of(Duration.ofMinutes(5)).advanceBy(Duration.ofMinutes(1))) | |
| .aggregate(() -> CreditCardTransactionAggregationDto.builder().ongoingTransactions(Set.of()).build(), | |
| (key, value, aggr) -> { | |
| final Set<CreditCardTransactionDto> current = aggr.getOngoingTransactions(); | |
| Set<CreditCardTransactionDto> set = new HashSet<>(current); | |
| set.add(value); | |
| return aggr.toBuilder() | |
| .ongoingTransactions(set) | |
| .build(); | |
| }, | |
| Materialized.with(keySerde, MySerdesFactory.creditCardTransactionAggregationSerde())) | |
| .toStream() | |
| .filter((key, value) -> hoppingWindowThreshold.compareTo(value.sumOngoingTransactions()) < 0) | |
| .mapValues(value -> CreditCardFraudDetectionDto.builder() | |
| .fraudFlag("Y") | |
| .suspiciousTransactions(value.getOngoingTransactions()) | |
| .build()) | |
| .filter((key, value) -> value != null) | |
| .map((key,value) -> new KeyValue<>(key.key(), value)); |
Single Period with 1-hour Inactivity Window
These acceptance criteria are mostly similar to the previous one. The only difference is in the window mechanism. The keyword here is a single period with an inactivity duration. Whenever you find this kind of requirement, it goes directly to the session window type.
| // full code at FraudDetectionTopology.java | |
| // session-windows | |
| final KStream<String, CreditCardFraudDetectionDto> session = | |
| input.groupByKey(Grouped.with(keySerde, creditCardTransactionSerde)) | |
| .windowedBy(SessionWindows.with(Duration.ofHours(1))) | |
| .aggregate(() -> CreditCardTransactionAggregationDto.builder().ongoingTransactions(Set.of()).build(), | |
| (key, value, aggr) -> { | |
| final Set<CreditCardTransactionDto> current = aggr.getOngoingTransactions(); | |
| Set<CreditCardTransactionDto> set = new HashSet<>(current); | |
| set.add(value); | |
| return aggr.toBuilder() | |
| .ongoingTransactions(set) | |
| .build(); | |
| }, | |
| (key, aggOne, aggTwo) -> { | |
| final Set<CreditCardTransactionDto> ongoing1 = aggOne.getOngoingTransactions(); | |
| final Set<CreditCardTransactionDto> ongoing2 = aggTwo.getOngoingTransactions(); | |
| Set<CreditCardTransactionDto> set = new HashSet<>(ongoing1); | |
| set.addAll(ongoing2); | |
| return aggOne.toBuilder().ongoingTransactions(set).build(); | |
| }, | |
| Materialized.with(keySerde, MySerdesFactory.creditCardTransactionAggregationSerde())) | |
| .toStream() | |
| .filter((key, value) -> sessionWindowThreshold.compareTo(value.sumOngoingTransactions()) < 0) | |
| .mapValues(value -> CreditCardFraudDetectionDto.builder() | |
| .fraudFlag("Y") | |
| .suspiciousTransactions(value.getOngoingTransactions()) | |
| .build()) | |
| .filter((key, value) -> value != null) | |
| .map((key,value) -> new KeyValue<>(key.key(), value)); |
Join
As a final step, we need to join those three upstreams into one single output stream. The join process itself is straightforward. However, the important part is which join types that we will use. We have to inform the suspicious transactions wherever upstream detects them. And if there are more than one upstreams that detect the suspicious transactions, we need to merge the transactions into a single output. So we will use an outer-join as a join type. Lastly, because this is a stream-to-stream join, we have to specify the join duration. Since all the upstreams run in parallel fashion, the one-second duration for join is enough.
| // full code at FraudDetectionTopology.java | |
| // suspicious trx always goes into these joins | |
| single.outerJoin(hopping, | |
| valueJoiner(), | |
| JoinWindows.of(Duration.ofSeconds(1)), | |
| StreamJoined.with(keySerde, creditCardFraudDetectionSerde, creditCardFraudDetectionSerde)) | |
| .outerJoin(session, | |
| valueJoiner(), | |
| JoinWindows.of(Duration.ofSeconds(1)), | |
| StreamJoined.with(keySerde, creditCardFraudDetectionSerde, creditCardFraudDetectionSerde)) | |
| .to(CREDIT_CARD_FRAUD_DETECTION_OUTPUT, | |
| Produced.with(keySerde, creditCardFraudDetectionSerde)); |
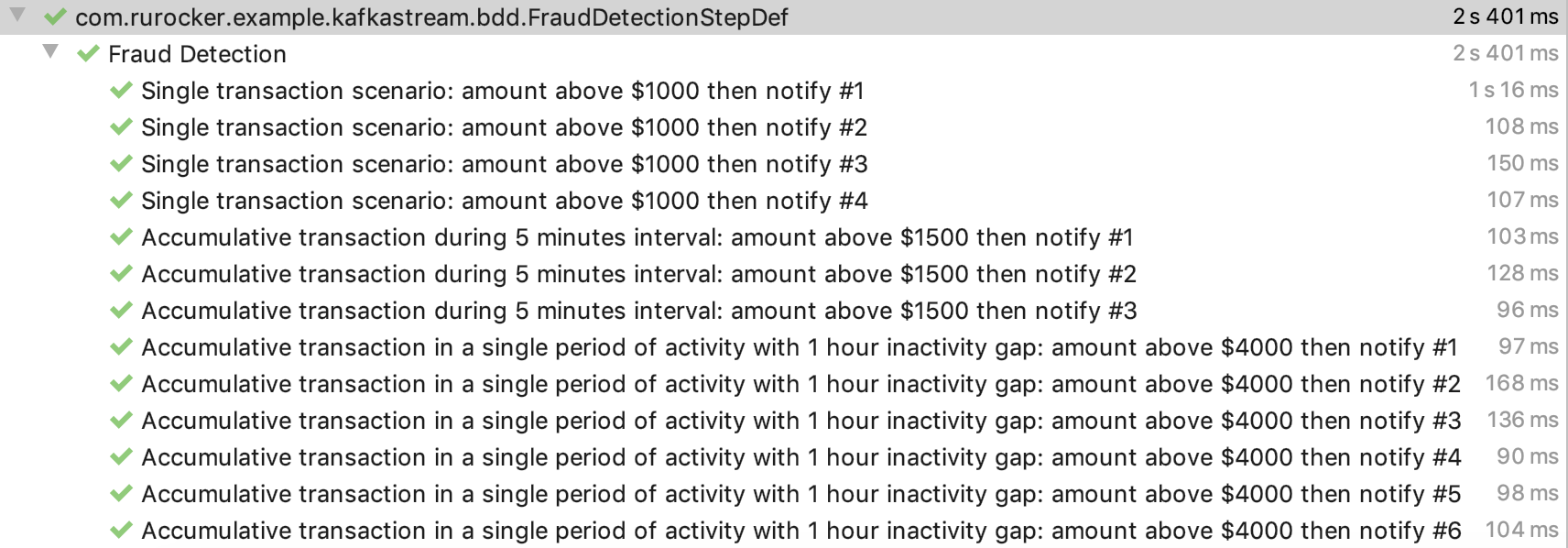
Run Test
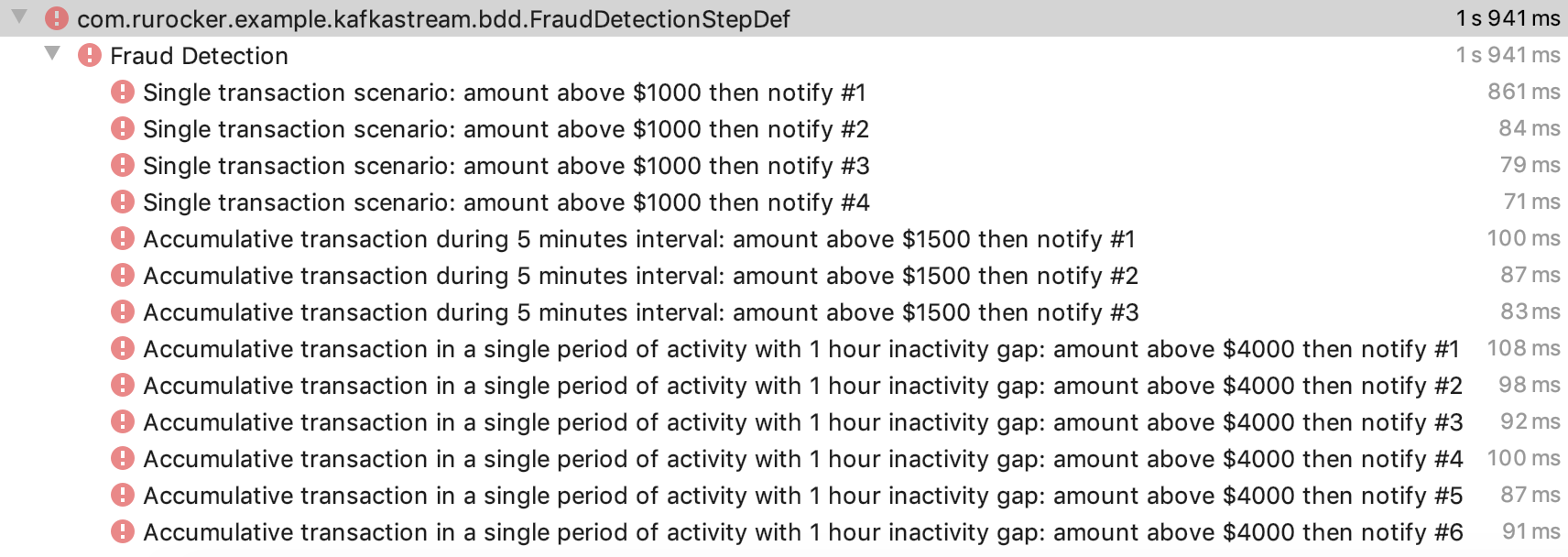
Once we complete the implementation, it is time to execute once again the test cases. If everything goes well, then you will get a GREEN result.

Conclusion
I reached the end of my study case for developing a very minimalistic fraud detection system. There are several takeaways:
- Data stream mechanism has several advantages for fraud detection due to its nature as event streams.
- Kafka streams simplify the feature implementation due to its filter, map, aggregate, group by, and windowing operations.
- To implement a feature entirely, you need to develop the feature and provide test cases.
- To have robust test cases, you need testable acceptance criteria that can be measured.
- To be able to measure the acceptance criteria, you need a good user story.
Therefore, unless you receive a good user story, you cannot complete your development process. And sometimes, a bad user story leads to a change request that can waste your existing sprint.
Remember garbage in, garbage out.
PS: you can see the full complete sample on my github repository.
References
- https://www.amazon.com/Mastering-Requirements-Process-Getting-Right/dp/0321815742
- https://www.visual-paradigm.com/guide/agile-software-development/what-is-user-story/
- https://cucumber.io
- https://kafka.apache.org/11/documentation/streams/developer-guide/dsl-api.html#windowing
One thought on “A Study Case: Building A Simple Credit Card Fraud Detection System – Part 2: Mapping Gerkhin to Kafka Streams”