A Food for Thought: How to Share Data Among Services in a Microservice World (part 2)
A microservice architecture is all about transferring data from one service to another.
Overview
In the previous article, we already discussed data sharing between services in the microservice architecture world. We talked about Direct Database Connection sharing and HTTP call mechanism.
Now we continue with the third and last option for this topic.
Messaging and/or Streams
The last option in today’s article is using messaging system. Because the almost similar between messaging and streams, I will put them into one sub-section.
tl;dr: I am just lazy to split them.
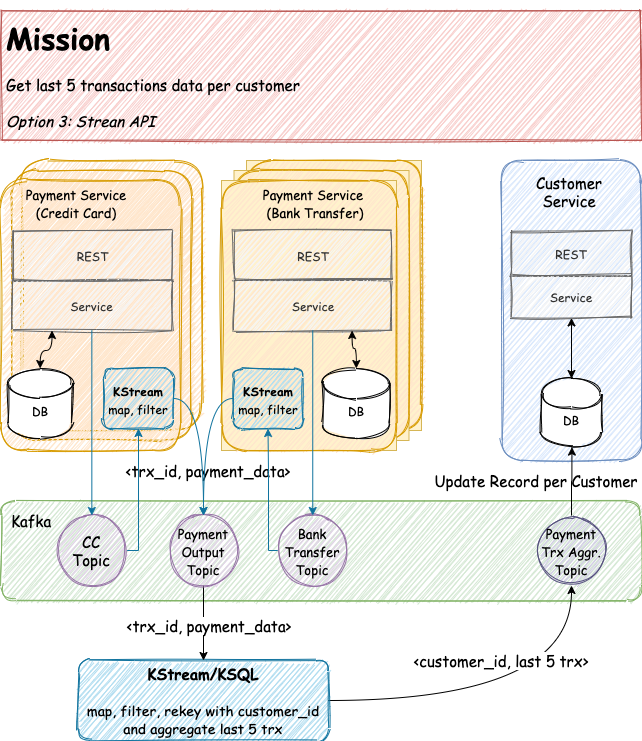
In this approach, every Payment Service writes down their transactions into a specific topic. Let say CC-PAYMENT for credit card payment topic and BANK-TRANSFER-PAYMENT for bank transfer topic. Moreover, each Payment Service has its stream API. The main purpose of each stream API is to transform different payment payloads into a single common payment data. Then store it back into PAYMENT-OUTPUT topic.
After the payment data is stored into the topic, we can build another stream API or KSQL to transform and aggregate all of them to produce the last five transaction information per customer. Then we store the information back to another topic, let say PAYMENT-TRX-AGGR topic. And Customer Service can fetch the information later and store it into its own database (or elsewhere).
De-coupling Architecture
With this approach, we can handle previous issues with the HTTP call mechanism. For instance, whenever there is a new payment channel, we only focus on developing the new one. In the Customer Service perspective, they even do not know whether there is a new payment channel or not. It is totally transparent. As long as the new service writes the information into the PAYMENT-OUTPUT topic, the aggregation will take place itself.
Whenever one of the Payment Service is down (or both), we still can display the transaction information to our customers. This is the main beauty of the stream approach. You have almost an independent service that is transparent to one another, and experience almost no impact if another service is having a problem. By combining messaging and data streaming approach, we manage to keep data flowing from one service to another.
Lastly, you do not need to worry about the over-flooding network by polling every 30 minutes. Messaging and stream API already implements reactive architecture. Instead of polling requests in every specific duration, it will react if there is a new message comes.
All of these are possible because this communication style is purely asynchronous. And we are flowing our data from and into Kafka. The only dependable component in this mechanism is Kafka itself.
Single Point of Failure?
Since every service connects to Kafka, there is a possibility that Kafka is becoming the new single point of failure. Well, we cannot escape the reality that at some point, every service and integration will face a critical point. But I tell you good news, Kafka was designed with distributed, scalability, and fault-tolerance configuration. So less worry about this issue.
Hard to Implement
To achieve this approach, it is not an easy task. First, we need to have a proper Kafka setup and infrastructure. Next, we need to have a team of developers who are ready to learn Kafka, either as a pub-sub or stream API. And the most critical is we need people who have a strong vision and collaboration from the beginning in order for our services to run seamlessly in the future. Someone who can oversee the flow of data within the organizations, as well as coordinate between multiple product development streams.
Eventual Consistency
Another important aspect of this approach is eventual consistency. There will be some delays to deliver data to its final stage. Therefore, our customer maybe will retrieve stale data for a certain amount of time. Usually, it takes less than 5 minutes to reach eventual consistency. But it depends on how you configure your stream API. In my opinion, it is still acceptable because stale data is still better than inconsistent data.
Code Sample
Hereby, I provided some code implementation to implement the stream API approach.
Credit Card Stream API
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// Credit Card Stream builder.stream("CC-PAYMENT", Consumed.with(Serdes.String(), MySerdesFactory.ccPaymentSerde())) .peek((key,value) -> System.out.println("(cc-payment) key,value = " + key + "," + value)) .mapValues( cc -> { PaymentDto paymentDto = new PaymentDto(); paymentDto.setAccountName(cc.getCardHolder()); paymentDto.setAccountNo(maskNumber(cc.getCardNo())); paymentDto.setBankName(cc.getIssuer()); paymentDto.setCurrency("IDR"); // assume all CC transactions are converted to IDR paymentDto.setCustomerId(cc.getCustomerId()); paymentDto.setTrxAmount(cc.getTrxAmount()); paymentDto.setTrxId(cc.getTrxId()); paymentDto.setTrxDate(cc.getTrxDate()); paymentDto.setPaymentType("CC"); return paymentDto; }) .to("PAYMENT-OUTPUT", Produced.with(Serdes.String(), MySerdesFactory.paymentSerde())); |
Bank Transfer Stream API
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// Bank Transfer Stream builder.stream("BANK-TRANSFER-PAYMENT", Consumed.with(Serdes.String(), MySerdesFactory.bankTransferPaymentSerde())) .peek((key,value) -> System.out.println("(btrf-payment) key,value = " + key + "," + value)) .mapValues( bank -> { PaymentDto paymentDto = new PaymentDto(); paymentDto.setAccountName(bank.getAccountName()); paymentDto.setAccountNo(bank.getAccountNo()); paymentDto.setBankName(bank.getBankName()); paymentDto.setCurrency(bank.getCurrency()); paymentDto.setCustomerId(bank.getCustomerId()); paymentDto.setTrxAmount(bank.getTrxAmount()); paymentDto.setTrxId(bank.getTrxId()); paymentDto.setTrxDate(bank.getTrxDate()); paymentDto.setPaymentType("BANK_TRF"); return paymentDto; }) .to("PAYMENT-OUTPUT", Produced.with(Serdes.String(), MySerdesFactory.paymentSerde())); |
Payment Aggregation Stream API
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Get last 10 trx builder.stream("PAYMENT-OUTPUT", Consumed.with(Serdes.String(), MySerdesFactory.paymentSerde())) .map((key, paymentDto) -> new KeyValue<>(paymentDto.getCustomerId(), paymentDto)) .peek((key,value) -> System.out.println("(payment-output) key,value = " + key + "," + value)) .groupByKey(Grouped.with(Serdes.Integer(), MySerdesFactory.paymentSerde())) .aggregate(PaymentAggregationDto::new, (custId, paymentDto, aggr) -> { aggr.setCustomerId(custId); aggr.add(paymentDto); return aggr; }, Materialized.<Integer, PaymentAggregationDto, KeyValueStore<Bytes, byte[]>> as("PAYMENT-AGGR-MV") .withKeySerde(Serdes.Integer()) .withValueSerde(MySerdesFactory.paymentAggregationSerde())) .toStream() .peek((key,value) -> System.out.println("(paymentAggr) key,value = " + key + "," + value)) .to("PAYMENT-TRX-AGGR", Produced.with(Serdes.Integer(), MySerdesFactory.paymentAggregationSerde())); |
Sample Output
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
{ "customerId": 1, "payments": [ { "trxId": 1598021035878, "trxAmount": 452000, "customerId": 1, "trxDate": "2020-08-21T14:49:55.878", "paymentType": "CC", "accountNo": "778783******1451", "accountName": "Fowler", "bankName": "DUKE BANK", "referenceNo": null, "currency": "IDR" }, { "trxId": 1598021035878, "trxAmount": 452000, "customerId": 1, "trxDate": "2020-08-21T14:43:55.878", "paymentType": "CC", "accountNo": "778783******1451", "accountName": "Fowler", "bankName": "DUKE BANK", "referenceNo": null, "currency": "IDR" }, { "trxId": 1598021035827, "trxAmount": 352000, "customerId": 1, "trxDate": "2020-08-21T14:43:55.827", "paymentType": "CC", "accountNo": "711782******9651", "accountName": "Fowler", "bankName": "DUKE BANK", "referenceNo": null, "currency": "IDR" }, { "trxId": 1598021035774, "trxAmount": 444000, "customerId": 1, "trxDate": "2020-08-21T14:43:55.774", "paymentType": "BANK_TRF", "accountNo": "4796348879", "accountName": "Fowler", "bankName": "ATOZ BANK", "referenceNo": null, "currency": "IDR" }, { "trxId": 1598021035669, "trxAmount": 124000, "customerId": 1, "trxDate": "2020-08-21T14:43:55.669", "paymentType": "CC", "accountNo": "396527******0238", "accountName": "Fowler", "bankName": "DUKE BANK", "referenceNo": null, "currency": "IDR" } ] } |
the sample is on my github repository.
Conclusion
I deliberately consider only three approaches. There is still plenty of options out there that you may want to implement, such as traditional messaging, dumb pipe, etc.
As stated in the beginning, there is no silver bullet for microservice communication. Each approach brings pros and contra. Remember, there is no black and white conclusion. In the end, it is you who decide which one is the best-fit solution for your organization.
One thought on “A Food for Thought: How to Share Data Among Services in a Microservice World (part 2)”